
Машинное обучение — путь к искусственному интеллекту
«Машинное обучение — это всего лишь попытка сделать машину, которая учится на своем опыте. Сегодня мы предполагаем, что разработка таких машин — самый быстрый путь к созданию настоящего искусственного интеллекта. Но чтобы компьютер стал разумным, должен случиться прорыв на стыке науки и искусства.
Machine Learning — новый инструмент, новый путь инженерии. Мы занимаемся машинным обучением в двух направлениях: улучшаем свои продукты — например, поисковик, краеугольный камень нашего бизнеса, — и строим совершенно новые продукты, которые раньше были просто невозможны. Есть несколько методов машинного обучения, которые сегодня применяются на практике».
«Supervised Learning — один из важнейших типов. Представьте, если бы вы учились играть в шахматы, а за вашей спиной стоял бы гроссмейстер и нашептывал, как ходить. Конкретный пример: автоматическая сортировка спама в вашей почте. Раньше программисты задавали определенные правила, например, если в тексте слово viagra написанно со странными символами — это на 99 процентов спам. Теперь же алгоритм изучает архив писем, которые были помечены как спам и не спам. Он делает это снова и снова и медленно, но верно становится лучше и лучше, определяет спам все точнее. Это очень успешная техника — и костяк многих систем».
Reinforcement Learning основывается на отрицательном и положительном отклике, или, иначе говоря, на опыте. Если приводить пример с шахматами: представьте, если бы вы учились играть, каждый раз проигрывали, но делали из этого выводы.
Метод спонтанного обучения (Unsupervised Learning) работает без вмешательства со стороны экспериментатора. Машина производит анализ структур данных, вычленяя из них какие-то общие паттерны. Мы, люди, владеем всеми тремя обозначенными способами. Но машины пока освоили неплохо только первый, и постепенно мы стараемся научить двумя другим.
Как именно учатся машины
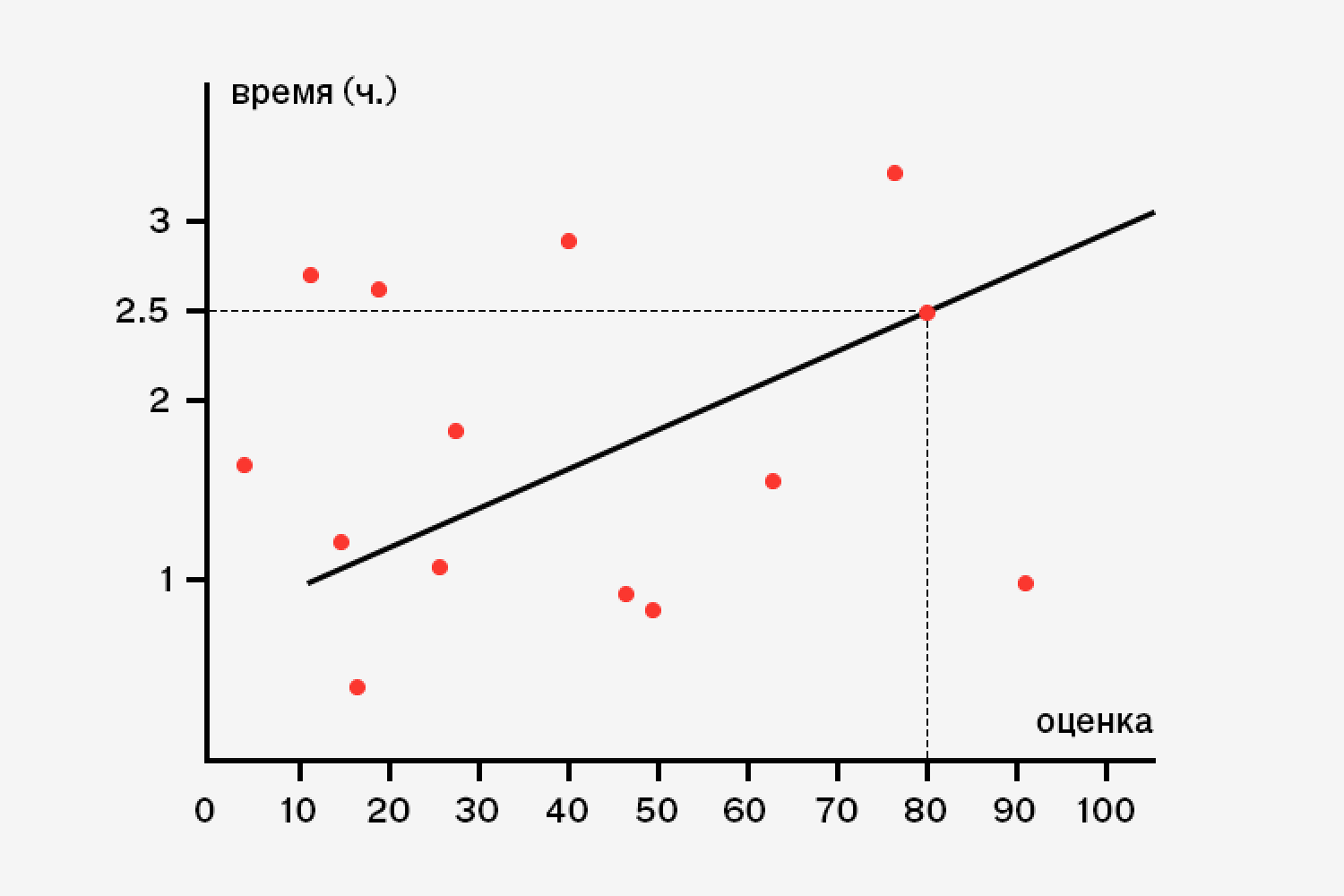
«Машинное обучение всегда имеет дело с вводом и выводом данных, и между этими процессами стоит некая математическая модель. Представьте, что нам нужно предугадать оценки учеников по тому, сколько времени они потратили на подготовку к экзамену. Конечно, казалось бы, чем дольше они занимаются, тем выше их оценки. Но вдруг тест очень легкий, и учиться не обязательно? Или, наоборот, тест ужасно трудный? Машина не знает эти тонкости, у нее нет житейского опыта. Как же ей просчитать эти закономерности?
Вообще, вся задача вписывается в линейный график Wx + B — это и есть искомая модель. Мы можем подставлять под значения W и B любые числа, которые берем из наблюдений: например, студент занимался два с половиной часа и получил оценку 80; затем мы обращаемся к другому наблюдению и будем продолжать заносить данные, сокращая ошибку прогноза. По прошествии времени с накоплением опыта мы получим график, который будет отображать общую тенденцию».
«Такая очень упрощенная система и есть суть программы машинного обучения. Одна ее часть — это входящие данные, математическая модель и набор параметров (чаще просто набор чисел); вторая — алгоритм, который сравнивает входящие данные и постоянно уточняет прогноз. Чтобы система совершенствовалась, она должна пройти этот путь миллионы и миллиарды раз. Поэтому мы только недавно пришли к ее созданию: компьютеры стали для нее достаточно мощными. И все равно они по-прежнему очень медленные ученики.
Другая проблема машинного обучения: мы должны иметь миллионы и миллионы примеров, тех самых входящих и исходящих данных. Сама система — это что-то вроде ракеты: умники вроде меня могут часами говорить о том, какая у нее должна быть форма, но она никуда не полетит без топлива. Эти данные — как раз оно и есть».

Что такое глубинное обучение
«Иметь дело с простыми уравнениями — это одно, но как, например, определить, что изображено на картинке? Нужна намного более сложная математическая модель. И тут на помощь приходит Deep Learning — специфический тип машинного обучения. По сути, это то, что называется искусственной нейронной сетью. Концепцию придумали еще в 1930-х, но важные математические расчеты для нее провели только в 1980-х. Главная особенность глубинного обучения в том, что оно основано не на одной функции, а на большом наборе.
В институте я учился не информатике, а нейронауке, то есть, по сути, я потратил 8 лет, чтобы понять, как мало мы знаем о мозге. Так вот компьютерные нейронные сети с большой натяжкой можно считать похожими на то, как устроен наш мозг. Но общее все-таки есть.
Вы воспринимаете эту информацию благодаря взаимодействию гигантского количества нейронов — индивидуальных клеток, из которых состоит мозг. Каждая из них сама по себе не разумна. Но она взаимодействует с другими нейронами поблизости, основываясь на том, как они преобразуют входящий сигнал в исходящий.
В нейронной сети Google вместо отдельных клеток-нейронов крошечные математические функции — может быть, чуть сложнее, чем Wx + B. Каждая из них ориентируется на множество вокруг. Миллионы и миллиарды математических функций работают вместе, и чем лучше они натренированы на это, тем сильнее система.
Эта технология и позволяет делать разные сумасшедшие вещи: подписывать фотографии, синтезировать искусство и даже выигрывать в го. Она также используется в распознавании речи и текста. Мы начали работать над нейронными сетями в 2011 году, и вы можете увидеть, как мы продвинулись за эти годы».

Как это применяется на практике
Мы не просто говорим о том, что нас ждет в будущем. Мы вовсю внедряем эти технологии. Например, распознавание речи в Google Now основано на Machine Learning, и за последнее время оно очень серьезно улучшилось. Мы также научились определять, что изображено на картинках, чтобы вам не приходилось вручную расставлять теги под фото в Google Drive. Мы используем эту технологию в машинном переводе: если раньше он по большей части основывался на правилах грамматики, то теперь на опыте — так же, как учат язык дети. По похожему принципу работает функция Smart Reply, которая составляет автоматические короткие ответы, если во входящем письме обнаруживается вопрос. Сейчас до 10% ответов в Gmail приходятся на эту функцию.
В ноябре 2015 года мы запустили TensorFlow — бесплатный софт, выпущенный под свободой лицензией Apache 2.0, который прекрасно подходит для машинного обучения и для проектов, связанных с Deep Learning. Мы хотели, чтобы эта система была бы достаточно гибкой как для исследований, так и для внедрения в продукты. Часто бывает, у кого-то появляется классная идея, как использовать машинное обучение для улучшения продукта, но чтобы ее внедрить, придется переписывать все с нуля. А этот инструмент позволяет улучшать продукты, не переделывая все полностью.